
Amit nem látunk, az nem is létezik? – avagy hol lakott az ősember
Jól tudjuk, hogy barlangokban? És honnan származik ez a tudás?
Jól tudjuk, hogy barlangokban? És honnan származik ez a tudás?

Az egyik legizgalmasabb statisztikai „fejtörő”, amivel tanulmányaim során találkoztam!

Valószínűleg tanulmányaid során találkoztál már vele – vagy legalábbis kellett volna!

Két csoport összehasonlítása – ha a szórásokra is figyelünk!
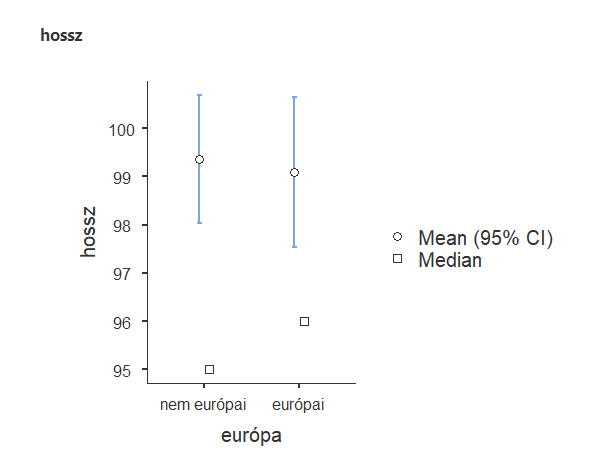
Röviden: ami közös bennük, hogy mindkettőt két csoport összehasonlítására használjuk.

Hány napot vesz el tőlünk egy szál cigaretta elszívása?

A „small sample bias” egy veszélyes gondolkodásbeli torzítás!
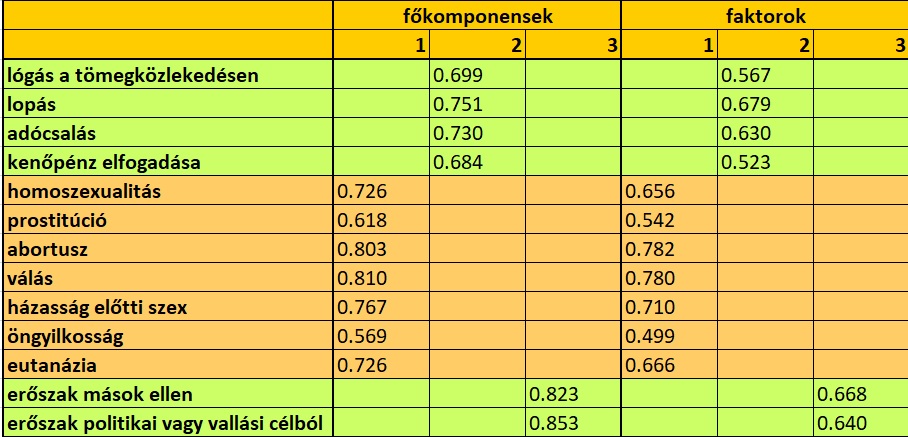
A többváltozós statisztikában gyakran kell erről döntenünk!
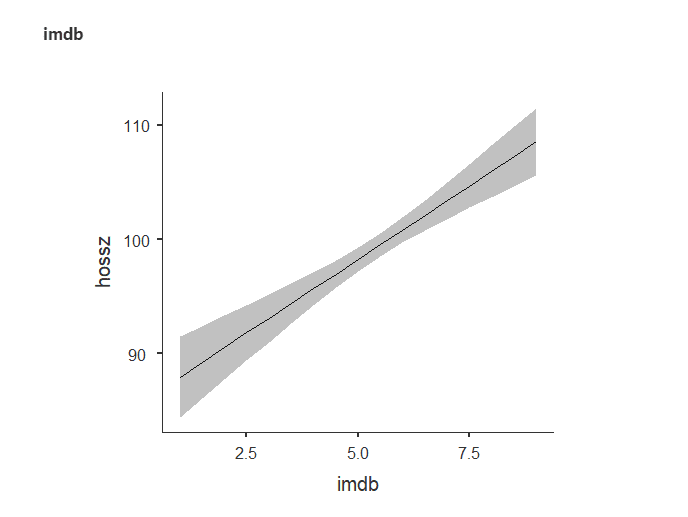
Érdemes tudni, akár egy vizsgán is sokat segíthet!
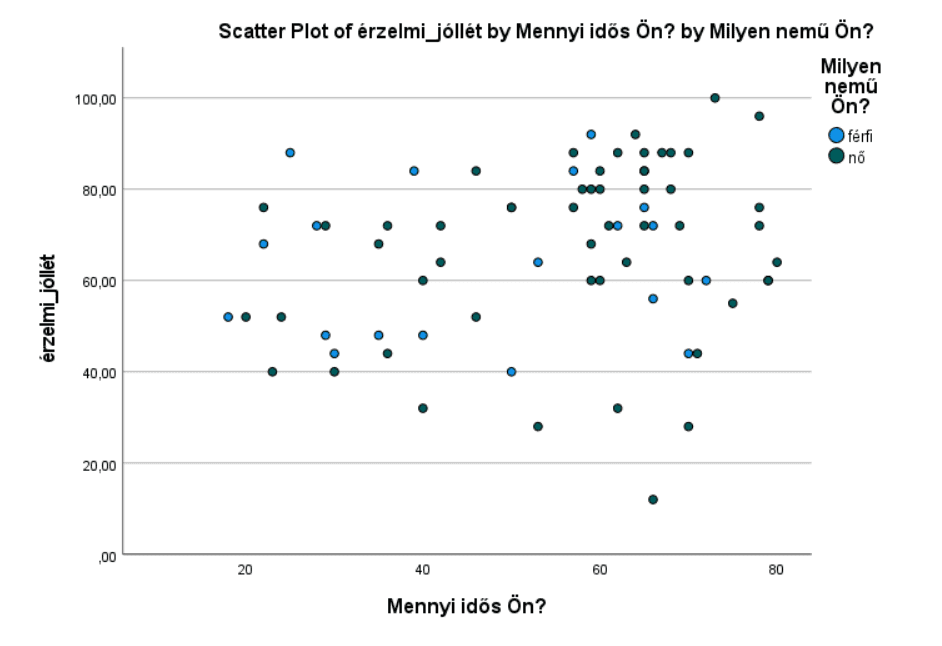
Látványos, sokatmondó, és lehetővé teszi egy harmadik változó megjelenítését.
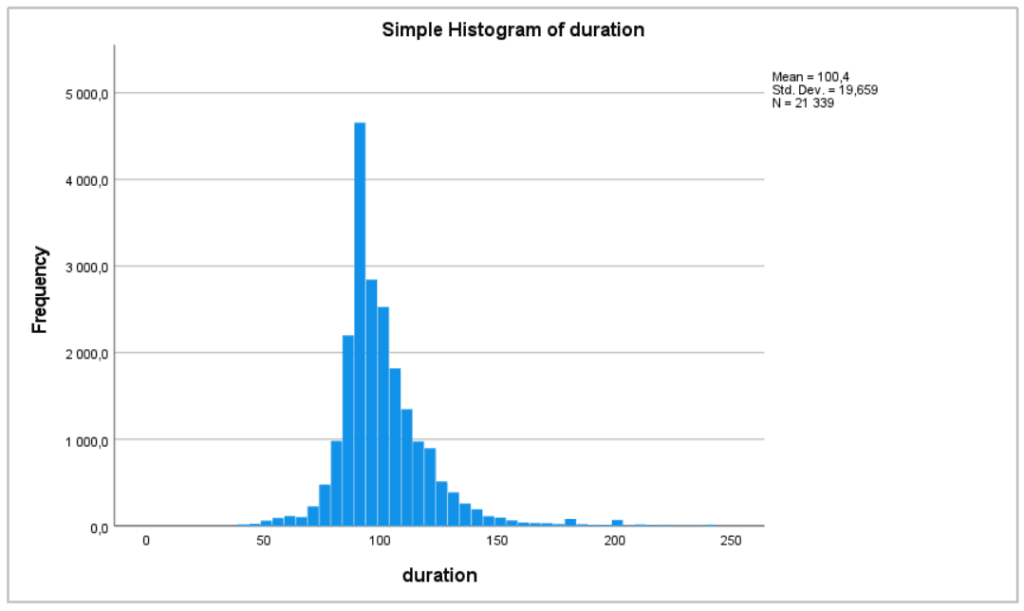
Mert az átlag hamis képet festhet, ezt pedig nem akarjuk!
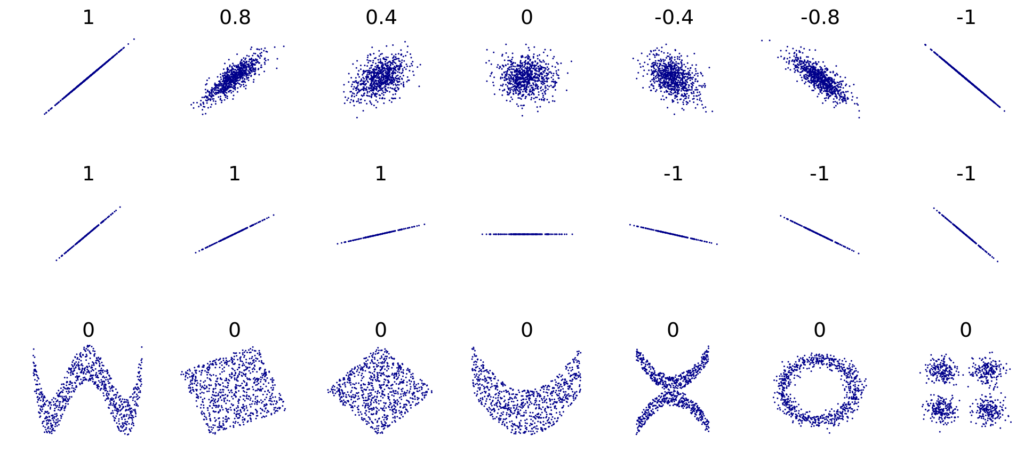
Erről mutatok egy rövid szemléltetést, érdemes észben tartani!