Nemrég járta be a sajtót a hír, hogy Nagy-Britanniában néhány évtizede tévesen számolták ki, hogy egy szál cigaretta átlagosan hány évvel rövidíti meg egy ember életét. A történtekről szóló cikkekben „jelentős módszertani hibákat” említettek, én pedig arra gondoltam, ezekből talán érdemes tanulni.
Mind a régi, téves, mind a frissebb, kiigazító kutatás Nagy-Britanniában zajlott; ez azért különösen érdekes, mert Anglia volt az egyik, ha nem a legjelentősebb ország a dohányzás európai elterjedésének történetében. I. Jakab király, és a dohányt az angolokkal megismertető Sir Walter Raleigh annyira nem szívelhették egymást, hogy miután vitatkoztak egy sort arról, be kell -e tiltani, vagy meg kell-e adóztatni a dohányzást, I.Jakab lefejeztette a Sir-t. A képen még fejjel együtt látható, miközben látványos pipájából boldogan pöfékel (a háttérben pedig a szolgáló épp készül vízzel eloltani gazdáját, azt gondolván, hogy az azért füstöl, mert meggyulladt):

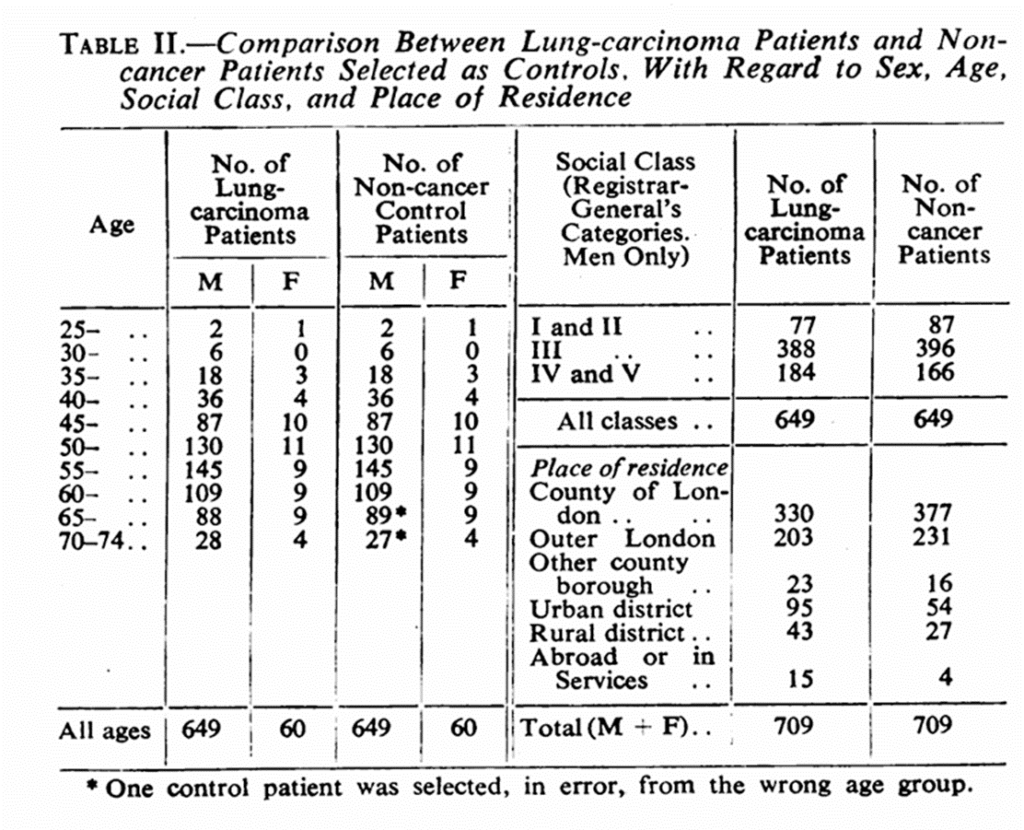
Egyszóval a szigetországnak és a dohányzásnak nagyon hosszú, közös története van; de ugyanez igaz a dohányzás káros hatásainak kutatására is. Sőt, brit tudósoktól származik az első olyan tanulmány, ami egészen komoly módszertannal, elsőként bizonyította be kétséget kizáróan, hogy a dohányzás tüdőrákot okoz. Ebben az 1950-es tanulmányban Doll és Hill szem előtt tartották például azt az irányelvet, hogy a kontroll-, és a hatásnak kitett csoportnak a hatáson kívül érdemes teljesen egyformának lennie, különben nem fogjuk tudni, mi okozza az eltérést a kimenetelben. Ez például egy fantasztikus táblázat arról, hogy hogyan alakultak az illesztett mintájuk számai (amikor is nem, életkori sáv, társadalmi osztály, és lakóhely szerint is igyekeztek a beteg és nem beteg mintát illeszteni, hogy valóban csak a betegség ténye különböztesse meg egyik csoportot a másiktól):
Ugyanakkor a 2000-es eredeti, a British Medical Journal-ban megjelent kutatásban kizárólag férfiak egészségét és dohányzási szokásait vetették össze; ezen belül kizárólag férfi orvosokét. Az akkori eredmény szerint egyetlen szál cigaretta elszívása 11 perccel rövidíti meg az életet – és a másik félmondat, amit akkoriban a média már nem jelentetett meg – hogy ez a kijelentés csak akkor igaz, ha az ember Nagy Britanniában él, férfi, és orvos.
Egy adott mintából mindig csak arra a populációra következtethetünk vissza, amiből a mintát vettük! Ha ezt nem tartjuk szem előtt, az úgynevezett lefedettségi hibát követjük el – mert nem látjuk a teljes populációt, mégis arra vonatkozóan teszünk becsléseket. A 2000-es kutatás eredményei csak a dohányzásnak a férfiakra gyakorolt hatásairól mondanak el valamit.
Az új kutatás egyébként a férfiakra vonatkozó számokat is korrigálta az újabb adatok alapján. Egyéb, potenciális összemosó változókra való kontrollálás után (társadalmi-gazdasági státusz, testmozgás) úgy becsülték, a férfiak életét átlagosan 17-; míg a nőkét 22 perccel rövidíti meg egyetlen szál cigaretta elszívása.
A tanulság tehát az, hogy akármihez is készítünk statisztikát (legyen ez publikáció, poszter, szakdolgozat), ne felejtsük el, hogy a következtetéseink csak arra a populációra lesznek kivetíthetőek, amelyből a minta származik!
Források:
Ennyi időt rabol el az életéből egyetlen szál cigaretta
Just One Cigarette Could Shorten A Smoker’s Life By 20 Minutes
The price of a cigarette: 20 minutes of life?
Mortality in relation to smoking: 40 years’ observations on male British doctors