…a statisztika ugyanis konkrétan egy külön szakma. Pszichológusoktól, orvosoktól, vagy neveléstudományi szakemberektől nem elvárható, hogy a statisztikához is professzionális szinten értsenek – hiszen az egy másik tudományág! Sajnos azonban a gyakorlat azt mutatja, hogy sok felsőoktatási intézményben mégis ezt az irreális elvárást támasztják a hallgatókkal szemben, ha korábban nem, a szakdolgozat statisztikai részének összeállításánál biztosan.
Ráadásul a statisztikát a legtöbb helyen nem is tanítják igazán jól, amiből az következik, hogy gyakran érthetetlen, mi is az egésznek a lényege. Például hogy miért kell hipotézisvizsgálat ahhoz, hogy eldöntsük, két átlag között van -e eltérés, mikor szemmel látható, hogy van? Szintén ki szokott maradni a képletekben használt jelölések ismertetése; pedig gyakran a képletek egy egész feladaton végigvezetnek, és segítenek abban is, hogy a számolási lépéseken helyes sorrendben haladjunk végig…
Sőt, már régóta kutatóként dolgozó szakembereknek is lehetnek fehér foltok a tudásában; hiszen egy kutatás felépítése és kivitelezése, majd az eredmények értelmezése nagyon összetett feladat, és egyáltalán nem biztos, hogy az előzetes tanulmányai során megfelelő felkészítést kapott az ilyen jellegű kihívások kezelésére az illető.
Tapasztalt statisztika magántanárként (15 éve magyarázok szinte nap- mint nap szignifikanciáról, anováról, normál-eloszlásról, korrelációkról, konfidencia-intervallumokról lelkes, és kevésbé lelkes tanítványoknak) pontosan tudom, mi az, amit a legtöbb egyetemen és főiskolán teljesíteni kell statisztikából. Azt is tudom, hogy mi az, amire már egy kutatás nulladik pillanatában érdemes figyelni, és mik azok a döntési pontok, ahol félrecsúszhat egy kutatás. És, bár én imádom a statisztikát, azzal is tisztában vagyok, hogy nem mindenki van ezzel így. Bízom benne, hogy a te, statisztikával kapcsolatos problémáidon is tudok segíteni, így ha szeretnél órára jelentkezni, vagy kérdésed van, vedd fel velem a kapcsolatot!
Egy kis csapat tagjaként részt veszek (én felelek a projekt statisztikai részéért) egy olyan kérdőív fejlesztésében, amely, magyar viszonylatban egyedülálló módon, képes lesz kimutatni, jellemző -e valakire az imposztor szindróma.
Ezen a linken már meg is találod a kérdőívet; a kitöltésével két dolgot is nyerhetsz: egyrészt Budapest Park utalványt 10ezer forint értékben; másrészt azt a boldog tudatot, hogy hozzájárultál a tudomány fejlődéséhez!
A kitöltéshez katt a képre; a kutatás részletesebb honlapját pedig itt találod!
Statisztikai tanulmányaink során jellemzően olyankor kerülnek szóba a mérési szintek, amikor még nem nagyon tudjuk mihez kötni őket. Nem segíti a megértési folyamatot az sem, hogy a skálák mérési szintjei azután összemosódnak a változók típusaival; és ez nem is csoda, hiszen a gyakorlatban inkább a változókkal dolgozunk, tehát ezekkel sokkal gyakrabban találkozunk. Sőt, a skálák mérési szintjeinek elnevezéseit gyakran változókategóriákként is használjuk…Mindehhez jön még az a jelenség, miszerint a változók többféleképpen is csoportosíthatók – és így válik teljessé a káosz. Sajnos viszont legkésőbb a szakdolgozat statisztikai részének összerakásához mindenképpen tisztában kell lenni velük!
A mérési szintek tulajdonképpen azt jelenítik meg, hogy egy-egy adat milyen módon alakítható matematikává. A nominális szintű adatok például sehogy; ezért is nominális, azaz névleges ennek a kategóriának a neve, mert a számok, amiket az adatokhoz rendelünk, egyáltalán semmiféle matematikai jelentéssel nem bírnak. Klasszikusan például 1-es jelöli a férfiakat, 2-es a nőket; de ezeket a számértékeket nincs értelme kivonni egymásból, sem összeszorozni, ésatöbbi. Csak címkék; ennélfogva elvben felcserélhetőek más címkékre; jelölhetné mondjuk 83 a férfiakat, és 243 a nőket, mivel ezekkel az értékekkel úgysincs értelme számolni. Ugyanígy lehetne például arról gondolkodni, hogy kinek milyen háziállata van. Lehetne 1-es a kutya, 2-es a macska, és 3-as az egyéb; de a kategóriákat számozhatnánk teljesen máshogy is; legfeljebb ahhoz lenne érdemes ragaszkodni, hogy az „egyéb” kategória, mint afféle „maradék”, legyen a legutolsó számérték.
Ezzel szemben mondjuk a településkategóriákat (főváros, megyeszékhely, város, község, egyéb) nagyon furcsa lenne nem a nagyságrendjüket lekövető számokkal jelölni. Ugyanez igaz a végzettségi szintekre. Elviekben jelölhetné 4-es az általános iskolát, mint legmagasabb végzettséget, és például 2-es a mesterképzést, 1-es pedig az érettségit; de ebben az esetben nem használnánk ki a mérendő értékek közötti természetes sorrendet. Ha tehát létezik egy ilyen természetes sorrend abban az adatban, amit számszerűsíteni akarunk, érdemes ordinális, azaz sorrendi skálát használni a mérésére. Így a kategóriák jelölésére használt számok, bár továbbra sem összeadhatóak, legalább az egymásutániságot megfelelően jelölik; további példa lehet erre a típusú adatra egy úszóversenyen résztvevők beérkezési sorrendje; vagy az egymást követő időszakok beszámozása egy idősoros elemzésnél.
A következő mérési szint az intervallumskála. Ezt olyan jellegű adatok számszerűsítésére használjuk, amelyek már rendelkeznek azzal a tulajdonsággal, hogy az általuk felvehető értékek között mindig azonos a távolság. (Szemben az előző, ordinális skálával, ahol az úszóverseny első és második helyezettének ideje között egyáltalán nem biztos, hogy ugyanakkora az eltérés, mint a második és a harmadik helyezett között; ott tehát az 1-2, és a 2-3 közötti „lépéshossz” nem azonos). Az intervallumskálán, éppen mivel már azonosak az osztásközei, az összeadás és a kivonás is értelmes eredményre vezet. Klasszikusan ezzel a mérési szinttel mér a hőmérő. Nagyon is van értelme azt mondani, hogy mivel ma 18 fok van, tegnap pedig 9 volt, ma 9 fokkal melegebb van, mint tegnap. Ugyanakkor a két érték osztással való összehasonlítása, ami arra az eredményre vezetne, hogy ma kétszer olyan meleg van, mint tegnap volt, megint csak nem értelmes fogalmilag, holott matematikailag nyilván tényleg kettőt kapunk, ha a 18-at 9-cel elosztjuk. Ha szeretnénk a szorzást és az osztást is értelmessé tenni a mérés során, akkor olyan skálát kell használnunk, aminek létezik úgynevezett abszolút nulla pontja.
Emlékszem, amikor én tanultam először a mérési szintekről, ezt az abszolút nulla dolgot egyáltalán nem értettem. Ha van egy abszolút nullánk, akkor már arányskáláról beszélünk; ami a nevében is mutatja, hogy ezen a mérési szinten már oszthatunk és szorozhatunk is. Így kell mérnünk például a testmagasságot. Mondhatjuk, hogy egy 160 cm magas ember 80 centiméterrel magasabb egy 80 cm magas gyereknél; de már azt is, hogy a 160 cm magas kétszer olyan magas, mint aki 80 cm. Tehát ami matematikailag nem működik a Celsius-skálán, az működik a testmagasságnál – és a két verzió között az abszolút nulla a különbség; ez pedig nem jelent mást, minthogy olyan skálával dolgozunk, aminél a 0, mint felvett érték lehetetlen; másképpen fogalmazva az a dolog, amihez a skálán 0 érték tartozna, az nem létezik. 0 fok, mint hőmérséklet- igen, ilyen van. 0 cm magas ember nem létezik, mint ahogy 0 kg tömegű ember sem. Abban azonban megegyezik az intervallum- és az arányskála, hogy mindkettő azonos osztásközökkel rendelkezik; a gyakorlati elemzési munka során nem is nagyon teszünk különbséget a kettő között.
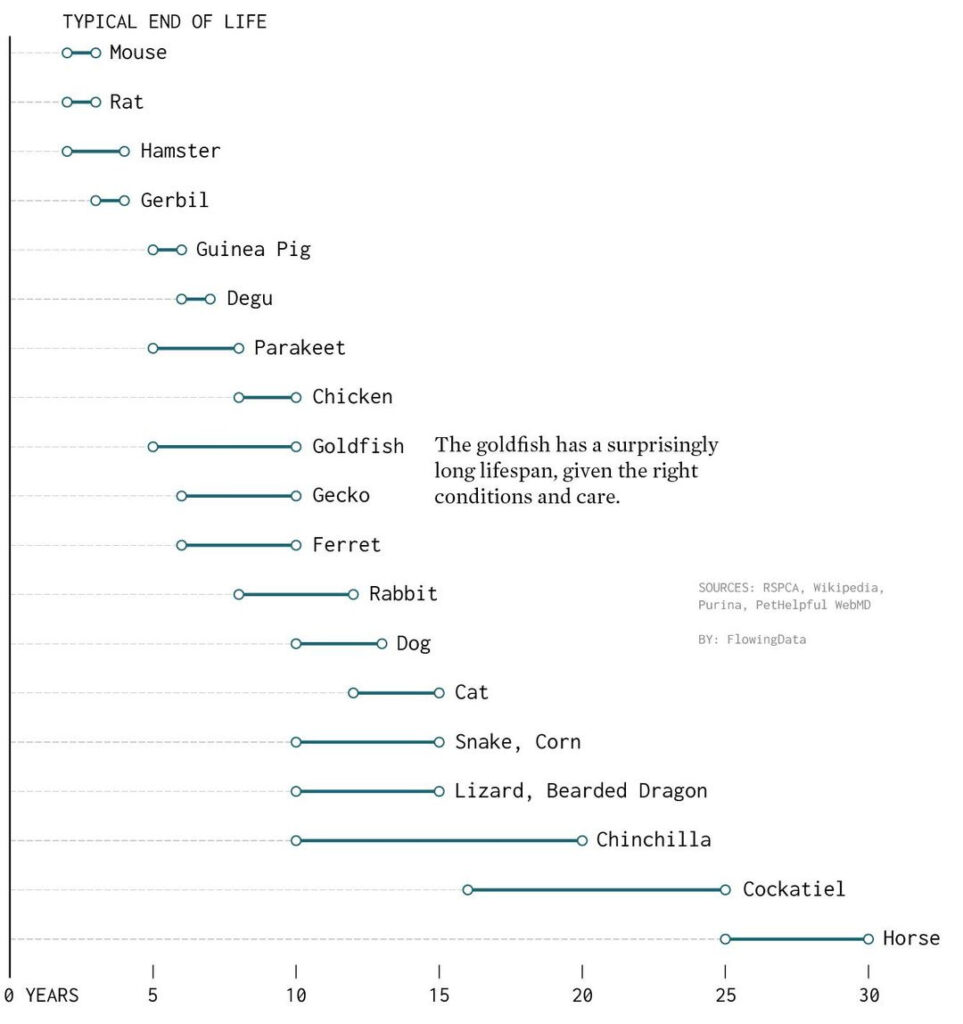
Alig néhány perccel azután, hogy a facebook-oldalamon megosztottam ezt a grafikont, két kérdést is kaptam hozzá kapcsolódóan. A kettő közül az, amelyikre röviden tudtam válaszolni, így hangzott, idézem: „milyen állat a corn?” (megfejtés: kígyó).
A másik viszont hosszasabb kifejtést igényel, nevezetesen hogy miért nem konkrét átlagértékeket látunk a grafikonon; vajon miért van minden állat mellett egy szakasz?
Lépjünk néhányat vissza, és nézzük meg, hogyan lehet a kérdésre válaszolni: átlagosan meddig él egy házimacska? Nyilván adatokat kell gyűjtenünk konkrét macskák élettartamáról (hogy ezt hogyan, mikor, milyen feltételekkel érdemes csinálni, most ne firtassuk); a képzeletbeli kutatásunkban ugorjunk oda, amikor van egy, mondjuk 100 adatot tartalmazó adatbázisunk macskák életéveinek számával.
Az első lépés nyilván az lesz, hogy átlagot számolunk a 100 értékből; legyen mondjuk ez 13,5 év. Ez a szám azonban csak a 100, a mintánkban szereplő cicáról mond el valamit – minket viszont általánosságban érdekelne, meddig élnek a macskák.
Ha a mintából az összes cica élettartamára következtetünk, akkor statisztikai terminológiával élve becslést végzünk. Ehhez kell némi bátorság előzetes tudás, de ha nagyon egyszerűen gondolkodunk, mondhatjuk, hogy mivel a minta átlaga 13,5; az összes cica, akire a becslés vonatkozik, átlagosan 13,5 évet fog élni. Sőt, csak egy átlag birtokában ennél sokkal jobb értéket nem is tudunk kijelölni az összes cica életkorára; hiszen indokolatlan lenne mondjuk 13, vagy 16 évet mondani, ha egyszer a minta átlaga 13,5 lett.
Viszont, hála a valószínűségszámítás és a matematikai statisztika csodálatos módszertanának, ennél azért tovább is tudunk menni. Számszerűsíteni lehet ugyanis azt, hogy bizonyos keretek között mekkora hibára lehet számítani amiatt, hogy egy mintából következtetünk egy sokkal nagyobb elemszámú, vagy éppen végtelen elemszámú sokaságra (más szóval populációra). Ezt a kalkulált hibát (tegyük fel, ez 1,5 év a példánkban) pedig arra tudjuk használni, hogy a 13,5 átlagot korrigáljuk vele. Ha kivonjuk az átlagból a hibát, majd hozzá is adjuk, egy olyan intervallumot kapunk, amiben minden cica átlagos életkora (egy bizonyos, előre meghatározott megbízhatósággal) benne van; nem pedig csak azé a százé, aki a mintába került. Egészen konkrétan ebben a példában a cicák átlagos élettartamának pontbecslése 13,5 év; intervallumbecslése pedig a 12 és 15 év közötti intervallum, jelöléssel: [12;15] – és, visszatérve a kiinduló kérdésünkre, ezt látjuk tól-ig a grafikonon.
Ha tudok a vizsgára készülésben, beadandók elkészítésében, a kutatásod megtervezésében, vagy elemzésben segíteni, vedd fel velem a kapcsolatot!
(A képen szeretett Katie cicánk, aki sajnos csak 14 évet élt.)
Most került elő a gépemről ez a pár évvel ezelőtti adatvizualizáció, amit egy workshop keretében készítettem. A workshop Barabási Albert László művészekkel foglalkozó projektjének része volt; a cél a magyar képzőművészek kapcsolatainak hálózatban való megjelenítése volt. Az ábrán egy konkrét képzőművésznő, és a vele valaha is együtt dolgozó művészek kapcsolódásai láthatóak; természetesen ez csak egy kis része lett a teljes képnek; a workshopon minden résztvevő egy képzőművész kapcsolati hálóját készítette el, és később ezek összekötéséből jött létre a kiállított mű. Izgalmas, és szép projekt volt.
A logisztikus regresszió módszere nem mindig kerül bele a statisztika alap-, vagy mesterképzés tananyagába, pedig nem bonyolult, viszont nagyon hasznos akkor, amikor a vizsgálni kívánt változó kategoriális.
Ebben a tanulmányban arra használtuk, hogy párok fogyasztásának egyenlőtlenségeit vizsgáljuk
Tapasztalataim szerint ez az egyik leginkább misztikusnak tűnő fogalom a statisztikában – és nem csak a diákok számára. Találkoztam már olyan kutatóval is, aki, bár évtizedek óta a pályán van, mégsem érti a lényegét, pedig nem is annyira bonyolult – csak valami furcsa okból épp ez (mármint hogy mi a célunk vele, mi az értelme) szokott kimaradni a statisztika bevezető órákról. Úgyhogy akkor most tisztázzuk is!
Amit mindenképpen érdemes megérteni: a hipotézisvizsgálat mindig a POPULÁCIÓRÓL mond el valamit, a MINTA alapján. Ezért képezik a hipotézisvizsgálatok a következtető statisztika egy jelentős szeletét; a koncepció nyilván mindenkinek ismerős. Van egy sokaság, egy populáció, amit meg szeretnénk ismerni, de nincs módunk megkérdezni/megvizsgálni/lemérni ennek a populációnak minden elemét – kiválasztjuk tehát egy részét(veszünk belőle egy mintát); és ha ezt a kiválasztást sikerült elég precízen megvalósítanunk, akkor a mintából tudunk a teljes populációra következtetni. Ha pedig van egy előzetes feltevésünk a POPULÁCIÓRÓL (például hogy benne azonos a férfiak és a nők átlagmagassága), akkor ezt a feltevést a mintából való következtetéssel tudjuk ellenőrizni – vagyis hipotézisvizsgálatot végzünk.
Emlékszem, amikor én tanultam először erről, én sem értettem a dolgot. Oké, van egy női átlagunk (mondjuk 167), meg egy férfi átlagunk (mondjuk 175), ezeket könnyen kiszámolhatjuk a mintából. Akkor vajon, gondoltam én, miért teszi fel a tanár a szemmel láthatólag szerinte fontos kérdést: „És akkor nézzük meg, eltér -e a nők és a férfiak magassága?”- hát persze hogy eltér, könyörgöm, az egyik 167, a másik 175, a vak is látja, hogy eltér…Azt hiszem, a tanárok már azzal nagyban segítenék a téma megértését, ha ilyenkor kiegészítenék a mondatot, valahogy így: És akkor nézzük meg, eltér -e a nők és a férfiak magassága a POPULÁCIÓBAN (a mintából következtetve…).
Ebből persze az is kiviláglik, hogy ha nem mintavétellel dolgozunk, vagyis ha megvan minden adatunk a populáció elemeiről (mint például egy cégnél az össze munkatárs fizetése), akkor ott értelmetlen hipotézisvizsgálatokat végezni, hiszen nem kell következtetnünk semmire, csak számolnunk kell.
Illetve még egy lényeges kiegészítés: a hipotézisvizsgálatok valószínűségekkel dolgoznak, következésképp BIZTOSAT semmiről a világon nem tudnak mondani – sem pro, sem kontra.
A lényeg tehát, első körben: hipotézisvizsgálatot akkor használunk, ha egy, a populációra vonatkozó feltevésünket akarjuk egy minta alapján igazolni. Ha nincs mintavétel, nincs értelme a hipónak sem; továbbá éppen mivel ismeretlen populációs jelenségekre következtetünk, biztosat a populációról sosem tudunk állítani; nagyon valószínűt vagy valószínűtlent azonban igen.
A lényeg második része hamarosan következik, egy újabb bejegyzésben!