
Darwin-napi pletykálkodás, avagy éljen február 12.!
A tudományos eredmények nem vákumban keletkeznek, és a következményeik sem állnak meg a „labor” falainál
A tudományos eredmények nem vákumban keletkeznek, és a következményeik sem állnak meg a „labor” falainál

Egy alig több, mint 5 perces videóban a lényeg!

Ebben a tanulmányban a logisztikus regressziót arra használtuk, hogy párok fogyasztásának egyenlőtlenségeit vizsgáljuk.

Köszönöm mindenkinek az együttműködést és közös gondolkodást!

Itt a felhasználónak kell észnél lennie, mert a szoftver „rosszul gondolkodik”! Új videó!

Jól tudjuk, hogy barlangokban? És honnan származik ez a tudás?

Az egyik legizgalmasabb statisztikai „fejtörő”, amivel tanulmányaim során találkoztam!

Valószínűleg tanulmányaid során találkoztál már vele – vagy legalábbis kellett volna!

Két csoport összehasonlítása – ha a szórásokra is figyelünk!
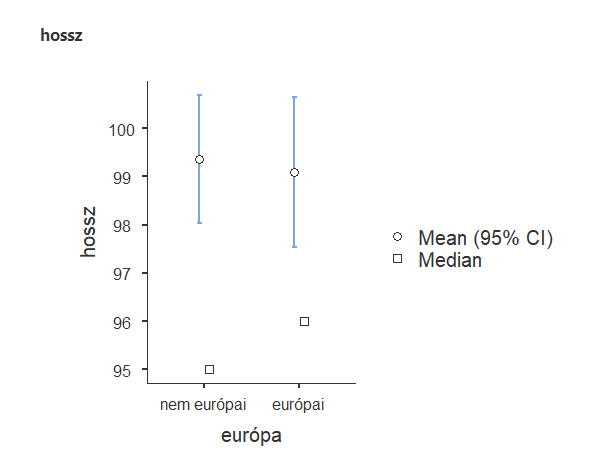
Röviden: ami közös bennük, hogy mindkettőt két csoport összehasonlítására használjuk.

Hány napot vesz el tőlünk egy szál cigaretta elszívása?

A „small sample bias” egy veszélyes gondolkodásbeli torzítás!