
Logisztikus regresszió – nem alap, de nagyon hasznos!
Ebben a tanulmányban a logisztikus regressziót arra használtuk, hogy párok fogyasztásának egyenlőtlenségeit vizsgáljuk.
Ebben a tanulmányban a logisztikus regressziót arra használtuk, hogy párok fogyasztásának egyenlőtlenségeit vizsgáljuk.

Köszönöm mindenkinek az együttműködést és közös gondolkodást!

Itt a felhasználónak kell észnél lennie, mert a szoftver „rosszul gondolkodik”! Új videó!

Valószínűleg tanulmányaid során találkoztál már vele – vagy legalábbis kellett volna!

Két csoport összehasonlítása – ha a szórásokra is figyelünk!
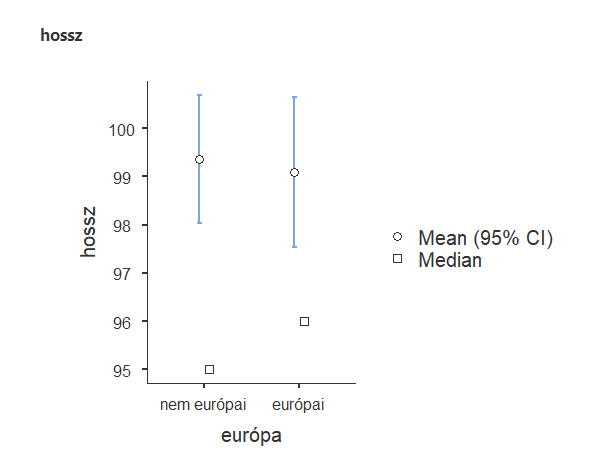
Röviden: ami közös bennük, hogy mindkettőt két csoport összehasonlítására használjuk.

Hány napot vesz el tőlünk egy szál cigaretta elszívása?
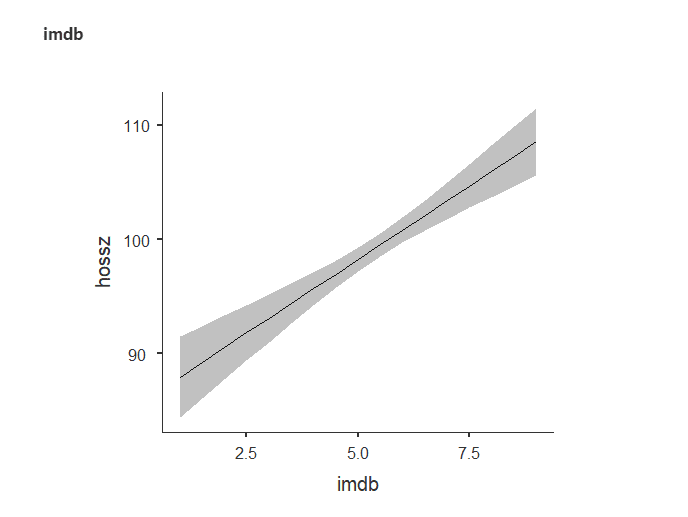
Érdemes tudni, akár egy vizsgán is sokat segíthet!
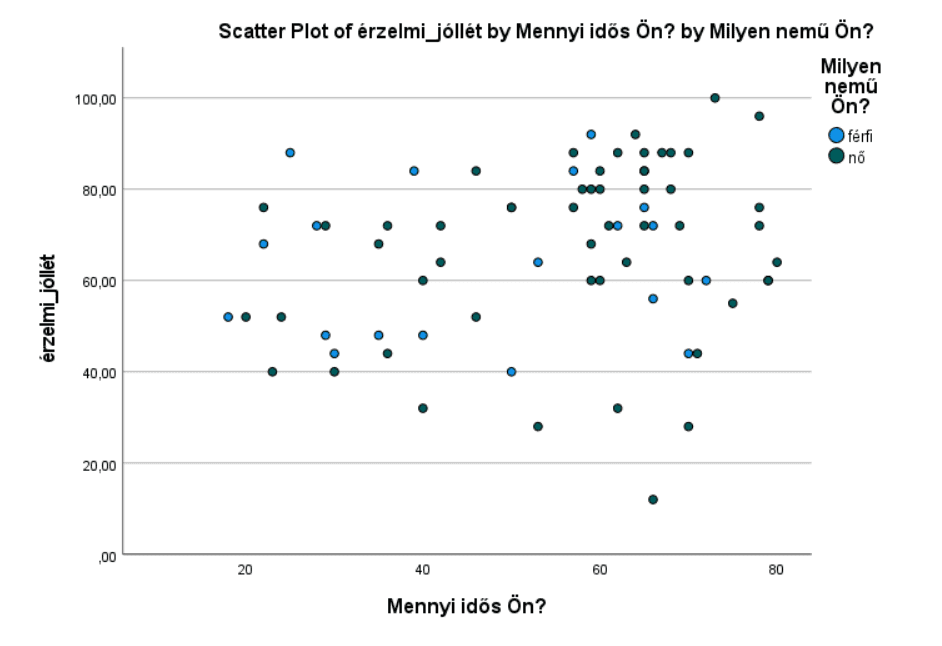
Látványos, sokatmondó, és lehetővé teszi egy harmadik változó megjelenítését.
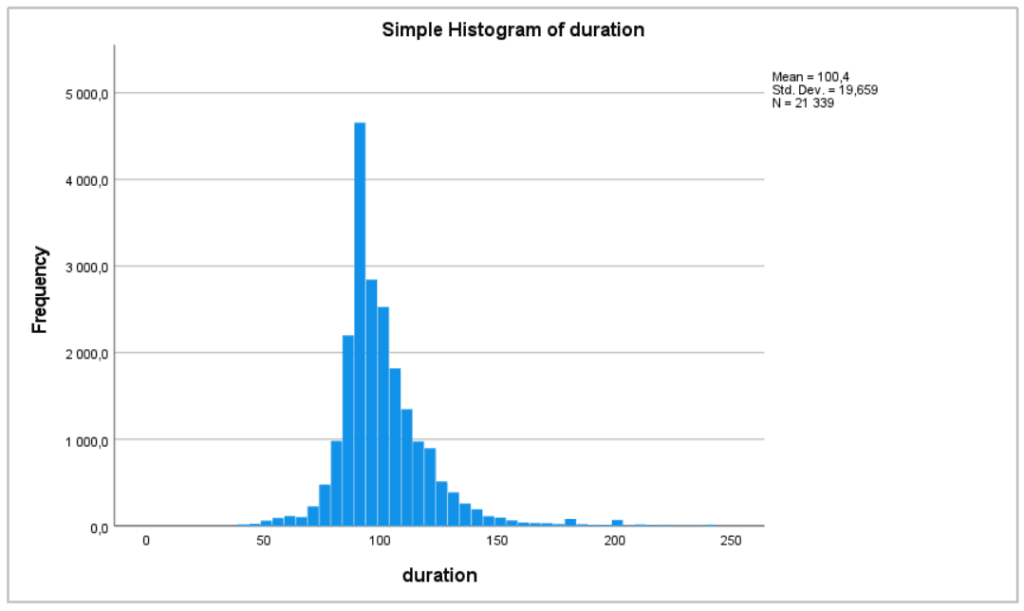
Mert az átlag hamis képet festhet, ezt pedig nem akarjuk!
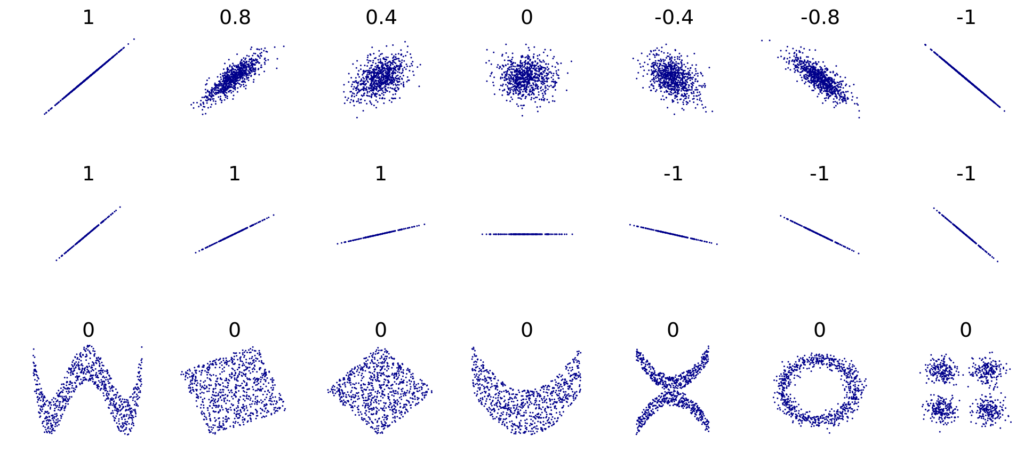
Erről mutatok egy rövid szemléltetést, érdemes észben tartani!

A statisztika ugyanis konkrétan egy külön szakma.