Számok a térdsebészet mögött: kutatásunk az elülső keresztszalag-műtétekről
Összesen 24 tanulmány-, és 866 beteg adatait összegeztük ebben a március végén megjelent szakirodalmi áttekintésünkben
Összesen 24 tanulmány-, és 866 beteg adatait összegeztük ebben a március végén megjelent szakirodalmi áttekintésünkben
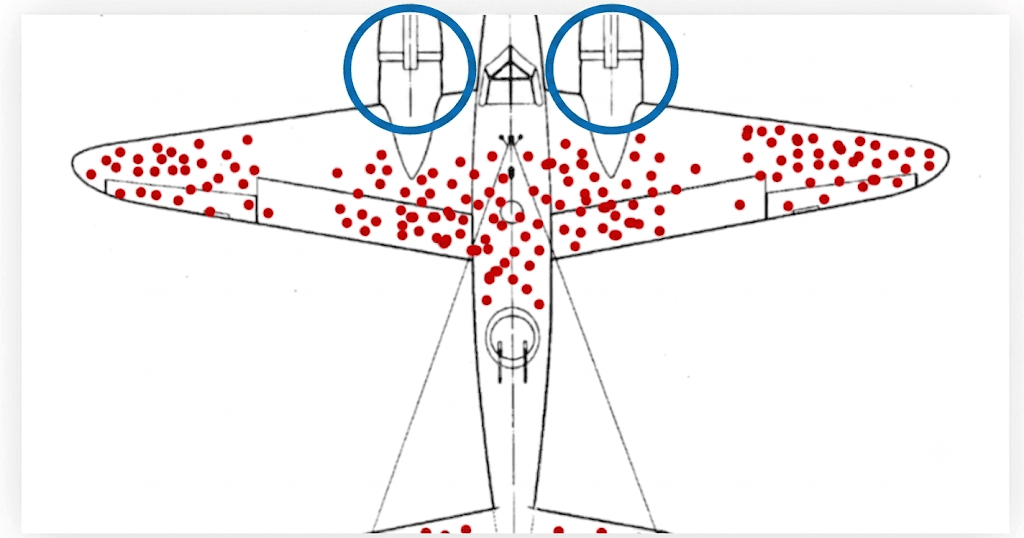
Klasszikus következtetési hiba, ha csak az orrunk előtt lévő adatokat használjuk – erről szól az újabb substack posztom!

Erről, és a polgármesterek fizetéséről elmélkedtem az első substack cikkemben!

…szemben a mai 8,3 milliárddal. Sir David ma 100 éves; következzen néhány érdekes tény a nagyszerű tudós-tudománykommunikátorról!

Néha érdemes kilépni a kétváltozós kapcsolatvizsgálatok világából; akár ezzel a két módszerrel!

A tudományos eredmények nem vákumban keletkeznek, és a következményeik sem állnak meg a „labor” falainál

Egy alig több, mint 5 perces videóban a lényeg!

Ebben a tanulmányban a logisztikus regressziót arra használtuk, hogy párok fogyasztásának egyenlőtlenségeit vizsgáljuk.

Köszönöm mindenkinek az együttműködést és közös gondolkodást!

Aki újra átnézné az előadás ppt-jét, az itt megteheti; találkozunk 2026.szeptemberben!

Kulliszatitkok az imposztor-jelenségről szóló kutatásunkról – szeretettel várunk mindenkit!

Itt a felhasználónak kell észnél lennie, mert a szoftver „rosszul gondolkodik”! Új videó!