
Egy klasszikus mintavételi hiba – a nem megfelelő lefedettség
Hány napot vesz el tőlünk egy szál cigaretta elszívása?
Hány napot vesz el tőlünk egy szál cigaretta elszívása?

A „small sample bias” egy veszélyes gondolkodásbeli torzítás!
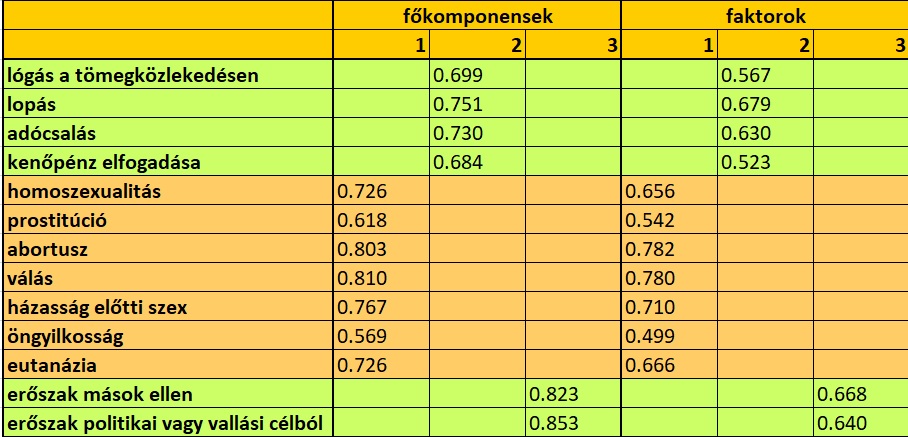
A többváltozós statisztikában gyakran kell erről döntenünk!
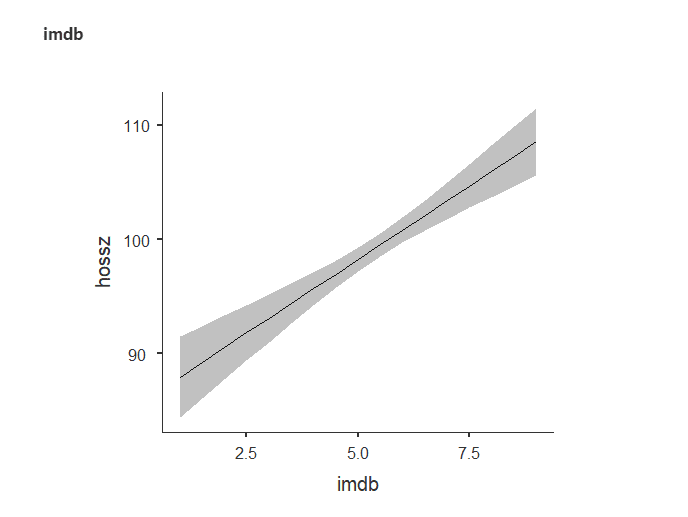
Érdemes tudni, akár egy vizsgán is sokat segíthet!
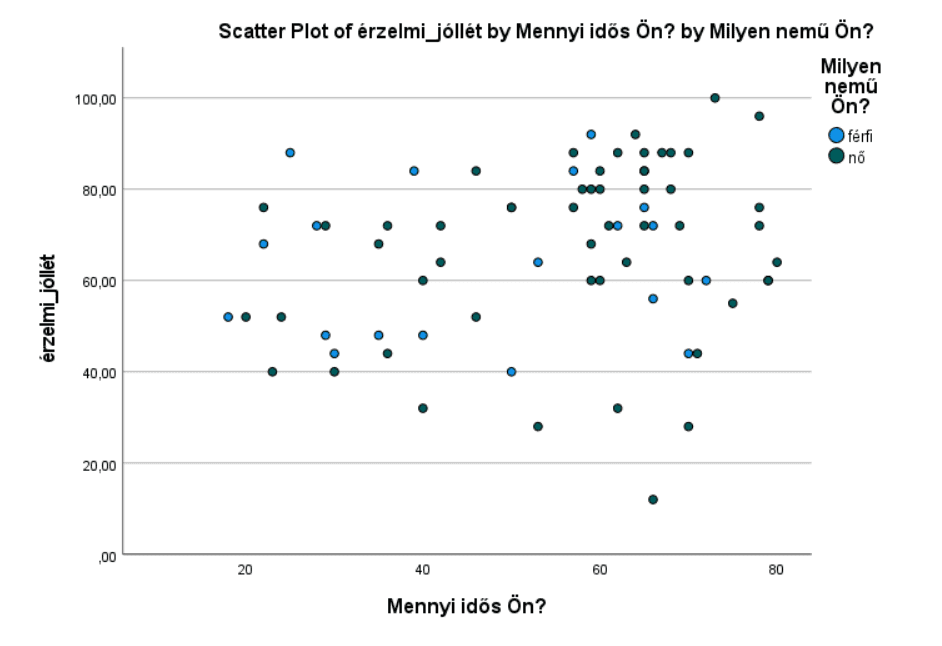
Látványos, sokatmondó, és lehetővé teszi egy harmadik változó megjelenítését.
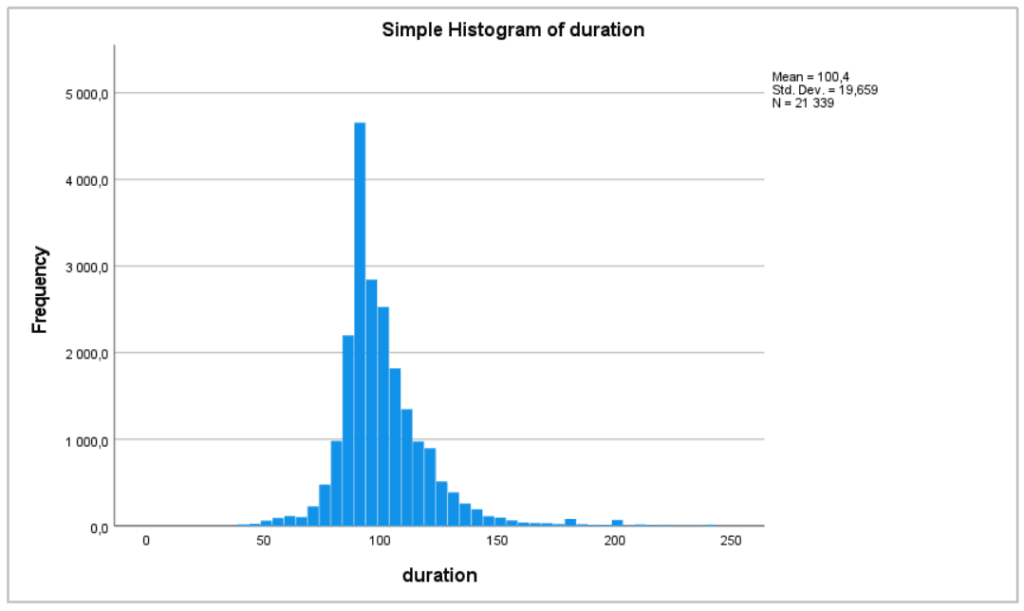
Mert az átlag hamis képet festhet, ezt pedig nem akarjuk!
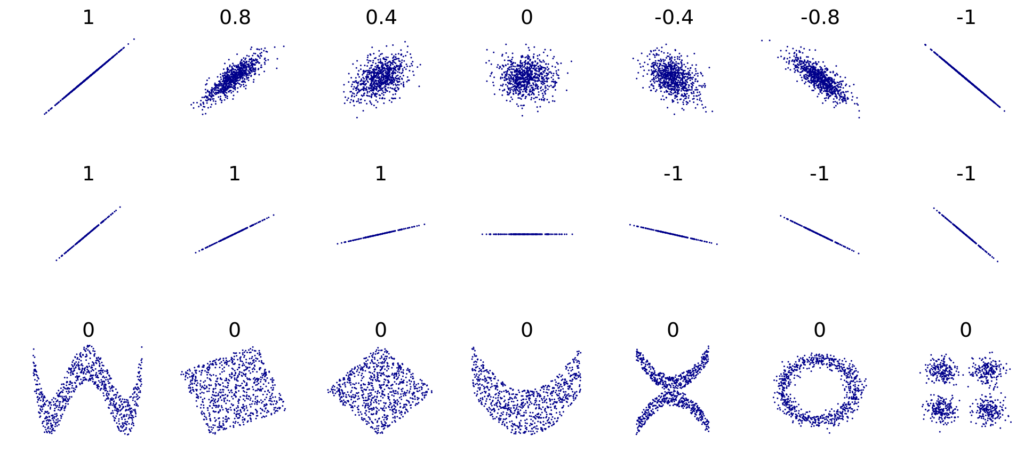
Erről mutatok egy rövid szemléltetést, érdemes észben tartani!

A statisztika ugyanis konkrétan egy külön szakma.

Csak néhány plusz kattintás, az eredmény áttekinthetőbb és látványosabb!

Erre szerencsére létezik egy egészen egyszerű szabály!

Töltsd ki a magyar viszonylatban egyedülálló kérdőívet!

Mindig ezzel kezdik az oktatást – így viszont lesz is mihez kötnöd!