
Több pontdiagram egyszerre SPSS-ben!
Csak néhány plusz kattintás, az eredmény áttekinthetőbb és látványosabb!
Csak néhány plusz kattintás, az eredmény áttekinthetőbb és látványosabb!

Erre szerencsére létezik egy egészen egyszerű szabály!

Mindig ezzel kezdik az oktatást – így viszont lesz is mihez kötnöd!
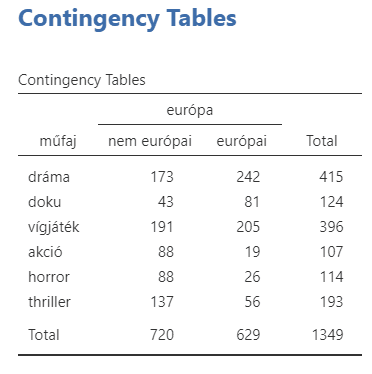
Ritkán van rá szükség a statisztikában, viszont akkor nagyon!

…hogy mondjunk általánosságban valamit arról, meddig élnek a háziállatok?

És akkor nézzünk szembe az igazi mumussal…-hipotézisvizsgálatok!
Folytassuk a mumus-szelídítést: tovább a hipotézisvizsgálatokkal!

Tanulmányokhoz, beadandókhoz, szakdolgozathoz hasznos lehet!