Címke: szakdolgozat

A változóredukció témakörénél gyakran felmerül a kérdés, hogy vajon mi a különbség a főkomponens-képzés, illetve a faktorképzés között. Valóban, a két eljárás eredményében lehet nagyon hasonló – ezt szemlélteti a következő táblázat, amit a World Values Study 7.hullámának adataiból készítettem; a következő változószett kérdéseivel (mennyire tartja elfogadhatónak az alábbiakat a válaszadó):
Justifiable: Avoiding a fare on public transport
Justifiable: Stealing property
Justifiable: Cheating on taxes
Justifiable: Someone accepting a bribe in the course of their duties
Justifiable: Homosexuality
Justifiable: Prostitution
Justifiable: Abortion
Justifiable: Divorce
Justifiable: Sex before marriage
Justifiable: Suicide
Justifiable: Euthanasia
Justifiable: Violence against other people
Justifiable: Terrorism as a political, ideological or religious mean
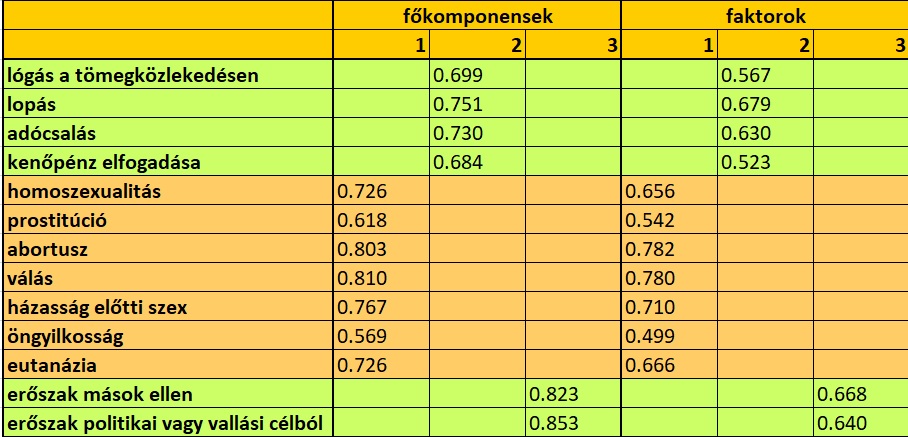
Látható, hogy a 13 változó ugyanúgy rendeződött 3 csoportba mindkét eljárás esetén; a különbség csupán a töltésekben van – erre még visszatérünk. Matematikailag is szinte ugyanaz a folyamat zajlik a két módszer alkalmazása során; és bizonyos szempontból a céljuk is ugyanaz, sok változóból kevesebbet csinálni – vagyis adatredukciót végezni.
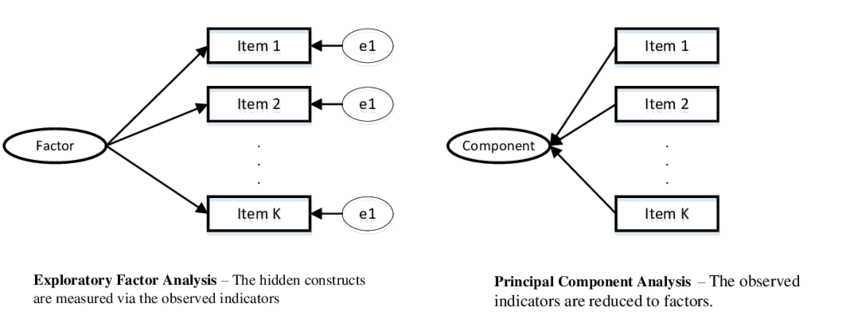
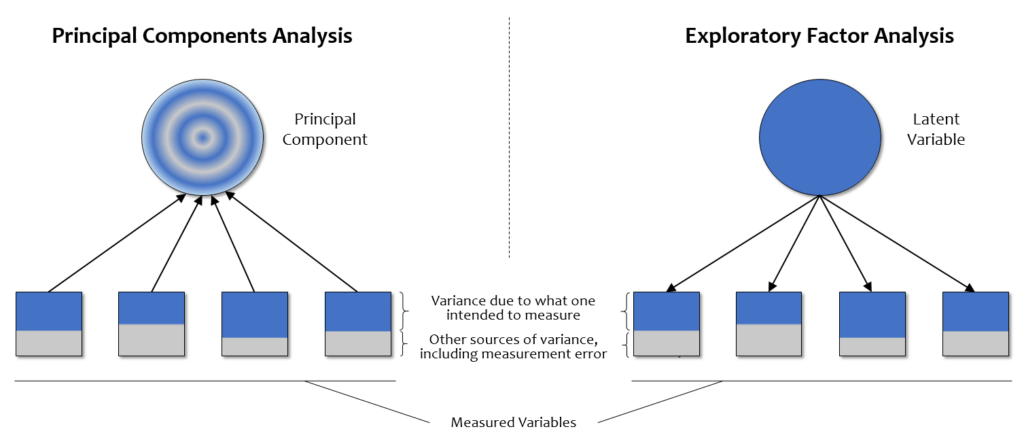
Szokás úgy fogalmazni, hogy a faktorelemzés során úgynevezett látens tényezőket keresünk, vagyis a változók mögötti, rejtett magyarázó változókat; míg a főkomponens elemzésnél egyszerűen csoportosítjuk az adatokat; tehát a változók csoportokba rendezésének az iránya más, ezt szemlélteti az alábbi ábra. Először azt érdemes megfigyelni, hogy a faktorelemzésnél a változók felé mutatnak a nyilacskák (jelezve ezzel, hogy egy látens, mögöttes hatótényező a rendezőelv), míg a főkomponenses ábrán a nyilacskák a változókból indulnak ki (jelezve, hogy itt a változók összevonása mögött itt nincs rejtett hatótényező):
Ez az eltérés az irányokban jól értelmezhető, ha végiggondoljuk, hogy elemzőként két célunk is lehet egy ilyen változószettel. Egyrészt törekedhetünk arra, hogy valóban csak az adatredukciót szem előtt tartva kevesebb változóba sűrítsünk minél több információt (ebből lesznek a főkomponensek). Ugyanakkor próbálkozhatunk azzal is, hogy felderítsük, milyen gondolati sémákkal, vagy attitűdökkel rendelkeznek a válaszadóink; tehát a rejtett szerkezetet szeretnénk feltárni. Ez a rejtett szerkezet az adatainkban úgy fog megmutatkozni, hogy azokra a kérdésekre, amik hasonló gondolatokat, érzéseket váltanak ki a válaszadókból, egymáshoz hasonlóbb válaszértékeket adnak. Amögött tehát, hogy az első faktorhoz a tömegközlekedésen lógás, a lopás, a kenőpénz és az adócsalás tartoznak; de a többi változó másik faktorokon van, az a jelenség húzódik meg, hogy ez a négy dolog az emberek fejében egy kategória, és ez megmutatkozik abban, hogy ezek az adatok egymással jobban egybecsengnek, mint a többi kérdésre adott válaszokkal.
És éppen ez a döntő különbség a két eljárás között: faktorelemzésnél csak a közös hatótényezők érdekelnek minket, semmi más; míg a főkomponens elemzésnél minden egyéb hatás is. Ilyen módon a faktorelemzésnél egészen fontos hatásokat is figyelmen kívül hagyhatunk; ha azok nem közösek más változókra ható tényezőkkel, akkor a mi elemzésünkben csak hibának értékelődnek, így ha még egyszer rápillantunk az előző ábrára, érdemes azt is megfigyelni, hogy csak a faktoros ábrán láthatunk hibatagokat (e betűvel, mint error) jelölve.
És íme, az az ábra, ami szintén jól szemlélteti, hogy a változókban megmutatkozó, többféle varianciából a jobb oldali, faktoros ábrán a látens változó csak a közös résszel kapcsolódik össze; míg a főkomponens elemzésnél többféle variancia is bekerül a főkomponensbe:
Térjünk vissza még a főkomponens- és faktortöltések táblázatát (kiegészítve azzal, hogy a töltések az adott faktor vagy főkomponens és a változó korrelációját mutatják). Ha figyelembe vesszük, hogy a faktorok csak a közös varianciát jelenítik meg, míg a főkomponensek minden varianciát, érthető, hogy az előbbiek értéke kisebb, mint az utóbbiaké:
Összefoglalva a rövid válasz arra, hogy melyik eljárást mikor használjuk az, hogy ha érdekel minket, milyen rejtett hatótényezők működnek egy-egy változószettben, használjuk a faktorelemzést – ebben az esetben csak a mögöttes faktorok által megmagyarázott varianciát őrizzük meg a változóredukció során.Viszont ha egyszerűen csak minél hatékonyabban akarjuk kevés változóban összevonni az eredeti változóinkat, és belőlük minél több információt megőrizni, dolgozzunk főkomponens-elemzéssel.
Sajnos van, akinek már csak akkor jut eszébe, hogy a két dolgot egyeztetni kellene, amikor már nem lehet (értsd: lekérdezte a kérdőívet, és lezárult az adatfelvétel).
És mivel a kérdéseken ilyen módon változtatni már nem lehet, a hipotéziseket kell átformálni, farigcsálni, toldozgatni – ez nyilván sok pluszmunka, megtörheti az egész szakdolgozat ritmusát, arról nem is beszélve, hogy a konzulensek nem szoktak ennek örülni (na nem mintha ők nem szólhattak volna ELŐRE, hogy valami nem stimmel…)

Mondok egy példát. Ha az egyik hipotézised az, hogy a férfiak jobban szeretnek vidámparkba járni, mint a nők, akkor ez a feltételezés két változóról szól: az egyik a nem, a másik pedig hogy mennyire szeret valaki vidámparkba járni. Azt, hogy ki milyen nemű, ritkán felejtik el megkérdezni a kérdőívben – bár találkoztam már ilyennel is, de azért a válaszok erre a kérdésre szinte mindig rendelkezésre állnak, tehát a hipotézis fogalmai közül a „nem”-et tudjuk ezzel a változóval mérni (nagyon egyszerűen: lesz hozzá egy oszlopunk az adatbázisban). Kelleni fog viszont egy olyan kérdés is, ami pontosan azt méri, amit a hipotézisbe belefogalmaztunk: tehát a vidámparkba járás kedvelésének a mértékét. Nem nagyon lesz elég egy bináris kérdés: szeret -e vidámparkba járni, mert ez esetben a hipotézisben az a szó, hogy „jobban”, nehezen lesz értelmezhető – bár ez még nem megoldhatatlan, ha a szeret/nem szeret válaszok arányát teszteljük. Viszont a „Vidámparkba szeret inkább járni, vagy uszodába?” már valami eléggé mást mér, mint amit a hipotézsiben lévő fogalom takar, a „Mikor volt legutóbb vidámparkban?” pedig teljesen mást- ámbár minden, említett kérdés a vidámparkról szól.
A két utóbbi kérdésben közös, hogy a vidámparkba járás szeretete mellett új dimenziókat, új szempontokat is a kérdésbe fogalmaznak; az első egy összehasonlítás valami mással; a második pedig az időtényezőt emeli be plusz dimenzióként.
Érdemes a „Mennyire szeret vidámparkba járni?” kérdést feltenni, tehát nyelvtanilag érdemes minél kevesebb sallanggal, a lehető legjobban lekövetni a kérdéssel a hipotézisben szereplő fogalmat.
Mindenképpen jó elkerülni azokat a kérdéseket, amik nem csak egyetlen dolgot mérnek egyszerre; ha két tényezőre is kíváncsiak vagyunk, akkor tegyünk fel inkább külön kérdéseket rájuk. Ha az érdekel, hogy ki jár szívesen vásárolni, és hogy mikor szokott az illető vásárolni, akkor ne azt kérdezzük, hogy „Szeret -e vásárolni, és ha igen, mikor?”, mondjuk a következő válaszlehetőségekkel:
-gyűlölök vásárolni járni
-utálok vásárolni
-nem szívesen megyek vásárolni
-szeretek vásárolni, hétköznap délelőttönként
-szeretek vásárolni, hétköznap délutánonként
-szeretek vásárolni, hétköznap esténként
-szeretek vásárolni, hétvégén
Amellett, hogy pontosítani kéne, minek a vásárlásáról beszélünk, ezekkel a válaszlehetőségekkel az a gond (többek között), hogy nem adnak teljesértékű adatokat a két kérdésünkre: hogy szeret -e vásárolni (erre még csak-csak); de arról, hogy mikor szokott vásárolni járni, csak a vásárolni szeretőket sikerült megkérdeznünk… Vegyük inkább külön a két kérdést; az adatelemzésnél könnyebb dolgunk lesz, mert nem kell szétszedegetünk egy változóból a két fogalmat, és mert nem utólag derül ki, hogy ami igazán érdekel, arra egyszerűen nincs adatunk.
Az összemosó változókhoz szorosan kapcsolódó téma következik!
A mediációs elemzés hasznos lehet, amikor egy, két változó kapcsolatát vizsgáló, egyszerű modellt kiegészítve egy harmadik változó hatását szeretnénk igazolni. A mediátor változó olyan változó, ami kapcsolatot képez a független, és a függő változó között; valahogy így:
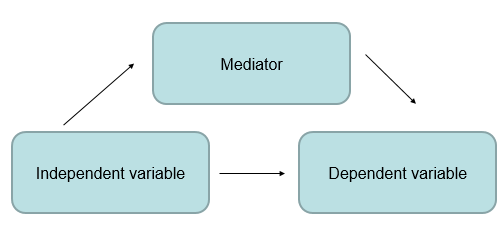
Egyrészt a független változó hatással van a függőre – ez természetes, ez az alapállás egy elemzésben; például az edzés mennyisége hatással van a sprintelés sebességére. Ugyanakkor a test magnézium-ellátottsága, mint mediáló változó, szintén hat a sebességre (minél kevesebb a magnézium, annál rosszabb a teljesítmény); és amitől a magnézium mediátor lesz, az nem más, minthogy az edzés elfogyasztja a szervezetből. Így tehát az edzés közvetetten (a magnéziumszint csökkentésén keresztül) IS hat a sebességre – ezért ha nem vesszük figyelembe egy elemzés során, nem fogjuk a teljes képet látni.
Egy másik példa lehet a következő hármas: matematikai képességek, és a matekszakon továbbtanulás iránti érdeklődés, mint független és függő változók – természetesnek vehetjük, hogy aki jobb matekból, azt jobban érdekli a matek-témájú továbbtanulás. És persze a harmadik változó, a példában a matekkal kapcsolatos önbizalom; ami közvetetten, a matekhoz való tehetség közvetlen hatása mellett, hat arra, vannak -e valakinek matek szakra továbbtanulási szándékai:
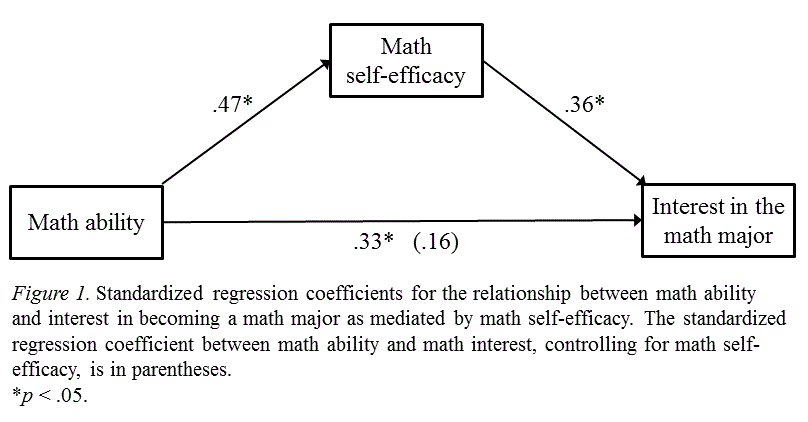
Az ábrán látható (a kis csillagok jelzik), hogy a közvetett és a közvetlen hatások is szignifikánsak; vagyis a matekos önbizalom általánosságban véve is (nem csak abban a mintában, amit éppen vizsgálunk) hat a továbbtanulási szándékra.
Mediációs elemzést SPSS-ben is végezhetünk, csak telepíteni kell hozzá az úgynevezett PROCESS makrót.
Összességében tehát ha túl akarunk lépni a gyakran félrevezető kétváltozós elemzéseken, érdemes a mediációs vizsgálatot is elővenni a statisztikai módszereink közül!
Fontos statisztikai alapvetés, hogy a kétváltozós elemzések nagyon félrevezetőek lehetnek,többek között az úgynevezett összemosó változók miatt. Az „összemosódás” egy olyan helyzet, amikor X és Y között a kapcsolat csak látszólagos, és csak azért találjuk meg egy elemzés során, mert egy harmadik változó jár együtt mindkettővel, egyszerre. Klasszikus példa a jelenségre a ráncok és az ősz hajszálak mennyiségének kapcsolata. Minél több a ránca valakinek, annál több az ősz hajszála is? Igen. Ha korrelációt futtatnánk, szoros kapcsolatot találnánk a két változó között? Minden bizonnyal. De mégsem a sok ránc okozza az ősz hajat, és nem is az ősz hajszálak magasabb aránya a több ráncot; hanem mindkettőt egy harmadik -mediátor, vagy itt specifikusabban összemosó változó- az életkor.
Itt van továbbá még a híres „gólya hozza a gyereket” sztori, tudományosan alátámasztva:

Itt az összemosó változó a falusias, vagy városias környezet; az urbanizáltság mértéke! A nagyvárosokban kevesebb a gólya, és átlagosan kevesebb gyereket vállalnak a párok. Érdemes megfigyelni, hogy a grafikon nem „hazudik”. Igaz, hogy minél több a gólya egy településen, annál magasabb a gyerekszám. Mindössze csupán két változó kapcsolatát boncolgatva ritkán látjuk a teljes képet-a világ általában komplexebb ennél.
Ezért minden, szakdolgozó tanítványomnak azt szoktam javasolni, hogy keressenek potenciális összemosó változókat egy-egy, a szakterületükön furcsának, meglepőnek számító, kétváltozós összefüggés mögött.
A válaszadóknak, vagy a kísérletben résztvevőknek LEGYEN SORSZÁMUK! Sok későbbi problémától megkíméled magad, ha a sorok beazonosíthatóak akkor is, ha sokadszorra rendezed őket eltérő módon, vagy ha valakit törölsz, ésatöbbi.
Szóval, ha a platform, ahonnan letöltöd az adatbázist, nem teszi meg automatikusan, akkor nulladik lépésként adj mindenkinek egyedi sorszámot. Apróság, viszont ennek hiányában nagyon keserves helyzetek állhatnak elő elemzés közben. Ha esetleg másik adatbázist, új változókat illesztenél az eredetihez, az egyedi azonosítók elengedhetetlenek. De egyszerűen csak ha többször eltérő szempontok alapján rendezted sorba a válaszokat; és szeretnéd visszaállítani ez eredeti verziót, akkor is kelleni fog egy változó, ami mentén ezt megteheted. Sorszámot mindenkinek!
