Most került elő a gépemről ez a pár évvel ezelőtti adatvizualizáció, amit egy workshop keretében készítettem. A workshop Barabási Albert László művészekkel foglalkozó projektjének része volt; a cél a magyar képzőművészek kapcsolatainak hálózatban való megjelenítése volt. Az ábrán egy konkrét képzőművésznő, és a vele valaha is együtt dolgozó művészek kapcsolódásai láthatóak; természetesen ez csak egy kis része lett a teljes képnek; a workshopon minden résztvevő egy képzőművész kapcsolati hálóját készítette el, és később ezek összekötéséből jött létre a kiállított mű. Izgalmas, és szép projekt volt.
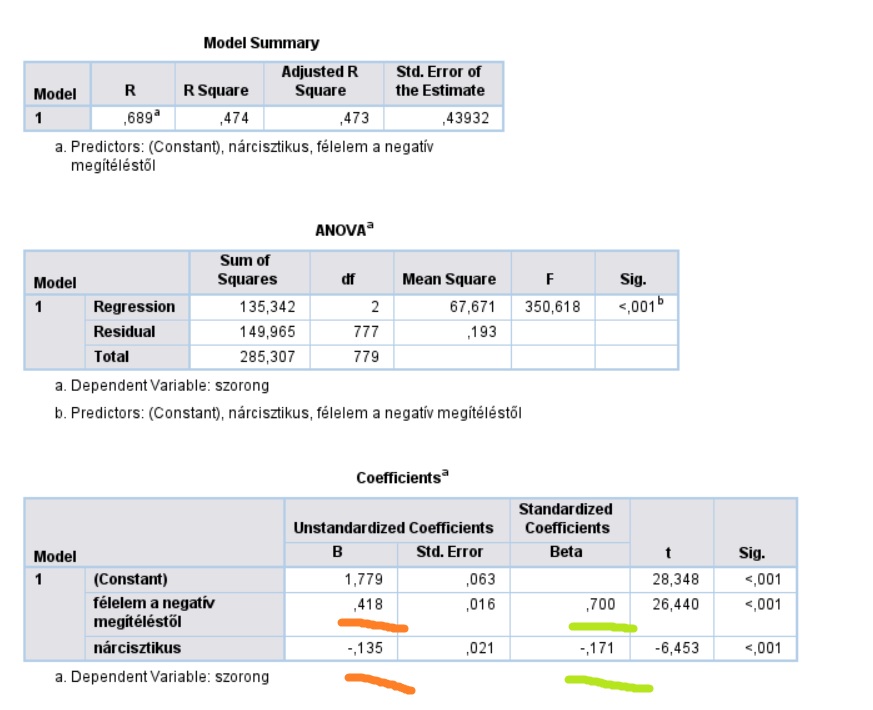
A statisztikában néha problémát okoz a különböző változók eltérő léptéke, mértékegysége. Így van ez a lineáris regressziónál is, ha több magyarázó változót vonunk a modellbe, amelyeknek eltérő a skálázása – ez azt eredményezi, hogy a regressziós együtthatókat nem tudjuk közvetlenül összehasonlítani.
Hiába derítettük ki például, hogy a csontsűrűséget átlagosan 0,2 egységgel növeli, ha 1 decivel több tejet iszunk naponta, és 0,4 egységgel, ha 100 grammal több sajtot fogyasztunk – nem mondhatjuk, hogy a tejfogyasztásnál a sajtfogyasztás kétszer nagyobb hatással van a csontsűrűségre, hiszen a tejet és a sajtot nem azonos mértékegységekkel mértük. Erre a problémára megoldást jelenthet valahogy összehangolni a sajt- és tejfogyasztás skálázását, mondjuk mindkettőt átváltani kalciumtartalomra; de létezik rá tisztán statisztikai módszer is – ezt pedig az SPSS lineáris regresszió outputjába szerencsére bele is építették.
A példa, amin ezt megmutatom, szimulált adatokra épül; azt „vizsgáltam” benne, hogy a félelem a negatív megítéléstől-, és a nárcisztikusság mennyiben befolyásolja a szorongást. Az outputban narancssárgával jelöltem a szokásosan értelmezendő, standardizálatlan, B együtthatókat – ezek szerint tehát a szorongás a neagtív megítéléstől való félelem 0,418 egységnyi növekedésével jár együtt; míg a nárcisztikusság egy egységnyi növekedése a szorongás 0,135 egységnyi csökkenésével (mindhárom változónál azt az eredeti mértékegységet tekintve „egységnek”, amiben eredetileg mértük őket).
Viszont ha szeretnénk valamit megállapítani a két magyarázó változó hatásának viszonyáról, akkor a zölddel jelölt, standardizált béta együtthatókat kell használnunk! Így tehát azt mondhatjuk, hogy a negatív megítélés nagyjából négyszer akkora (700/171), és ellentétes irányú hatással van a szorongásra, mint a nárcisztikusság.
[Két zárójeles megjegyzés: a regresszió esetében először a két együttható szignifikanciáját figyeljük, ha nincs szignifikáns hatás, magukat az együtthatókat nincs értelme firtatni – épp mert ekkor nincs hatásuk a kimeneti változóra a populációban. A második pedig, hogy a regresszióban csak akkor tudunk „hatásról”, tehát okságról beszélni, ha elméletileg is megalapozott, hogy a magyarázó változó okozza a kimenetit – ha ez nem teljesül, csak a változók „együtt járásáról” beszélhetünk.]
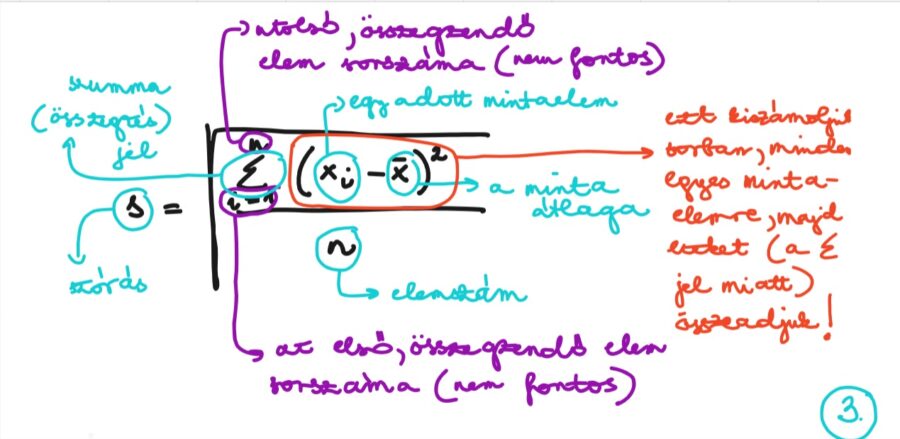
A számtani átlag és a szórás képletével szeretném bemutatni, hogyan értelmezhetőek a szummajelet tartalmazó képletek. A képek mellé magyarázatként néhány fontos dolog :
a szumma jel összegzést jelent (tehát gyakorlatilag sok, egymás utáni összeadást „rövidítünk”, vonunk vele össze)
ami a szumma jel alján és tetején van, annak szinte soha nincs a statisztikában jelentősége (ugyanis azt jelöli, hányadik elemtől hányadikig kell összeadni, és ez szinte mindig az elsőtől az utolsóig) (1. és 2. ábra)
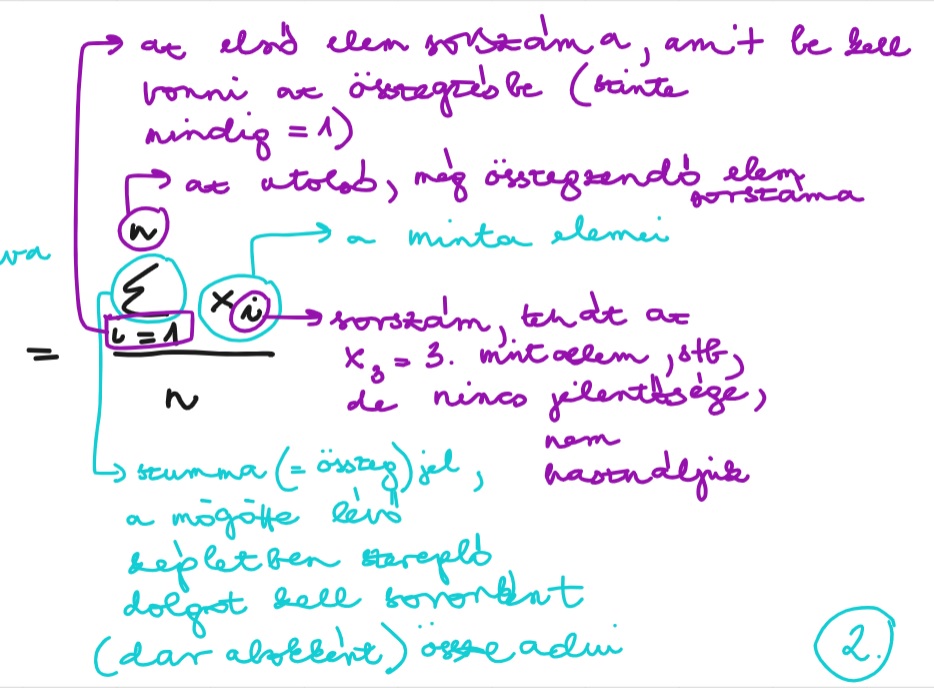
aminek viszont döntő jelentősége van, hogy a képletet, ami mögötte van, SORONKÉNT kell kiszámolni, és nem először összeadni, aztán pedig kiszámolni (3.ábra)
Tehát a fenti szórásképletnél, ha pl. a minta 3 elemű (4,5,6) – így az átlaga 5, a műveleti sorrend a következő:
-első mintaelem-átlag: ez itt most 4-5
-ezt négyzetre emeljük
-ugyanezt megcsináljuk az 5-tel és a 6-tal is
-majd az így kapott három értéket összeadjuk, és utána megyünk tovább az osztással, végül a gyökvonással
Bízom benne, hogy ez a poszt segít a képletek értelmezésében!
Ebben a tanulmányban például arra használtuk, hogy megpróbáljuk kimutatni, milyen javakat fogyasztanak egyenlőtlenül az együtt élő, heteroszexuális párok.
Az előző bejegyzésben tisztáztuk, hogy a hipotézisvizsgálatokat arra használjuk, hogy egy mintából a populációra következtessünk. Ennek a folyamatnak a során tulajdonképpen azzal próbálkozunk, hogy a véletlen hatását (ami a mintavételi ingadozáson keresztül valósul meg) a valós hatástól elkülönítsük; mindezt pedig valószínűségi alapon tesszük.
Folytassuk az előző posztban szereplő példával: eltér -e vajon a férfiak testmagassága a nőkétől a populációban? Mivel nem tudunk minden egyes embert megmérni, a populáció minden tagjának adatát képtelenség megismerni; ezért kénytelenek vagyunk egy mintából való következtetéssel beérni – ebben a mintában a nők magasságának átlaga 167 cm, a férfiaké 175. És, akármennyire precízen vettük is a mintát, abban megegyezhetünk, hogy egy másik minta egy kissé más átlagokat mutatna, egy harmadik pedig ismét eltérne kissé, a véletlen hatása miatt. Ha pedig ezt elfogadjuk, akkor honnan tudhatnánk, hogy a 167 és a 175 közötti eltérés nem csak egy extrém szerencsétlen mintavétel miatt van, hanem tényleges különbséget jelez?
Itt jön képbe a valószínűség. Mivel a nullhipotézis mindig az, amit leginkább „nincs itt semmi látnivaló”-nak nevezhetnénk (vagyis a példánkban, hogy nincs eltérés az átlagok között, tehát a populációban a férfiak és a nők testmagassága megegyezik), ebből az alapfeltevésből indulunk ki. Amikor a szignifikianciaszintet 0,05-ben határozzuk meg, akkor tulajdonképpen azt mondjuk, hogy a nullhipotézisben foglalt állításhoz képest leginkább valószínűtlen, lehetséges mintákat gondoljuk túl valószínűtlennek ahhoz, hogy a nullhipotézis fennállását még komolyan tudjuk venni (a lehetséges minták legextrémebb 5%-át). Egy határ után az eltérés a két átlag között már annyira valószínűtlen, hogy szinte képtelenül szerencsétlen mintát kéne vennünk hozzá, hogy az eltérés csak a véletlen műve legyen – márpedig ha nem a véletlen műve, akkor ott HATÁST találtunk (különbséget, összefüggést).
Ha a két nem testmagassága a nullhipotézisnek megfelelően tényleg egyezik, akkor például egy 168 versus 170-es nő/férfi mintaátlag még elképzelhető, mint a mintavételi ingadozás következménye. 168 és 172 cm is, „szemmértékre”. De ha a nő minta átlaga 168, a férfié 190, akkor érzékelhetően növekszik annak a valószínűsége, hogy mégsem stimmel a nullhipotézisünk. Ha az egyik átlag 140, a másik pedig 210 lenne (persze korrekt mintavétellel), akkor már nagyon nehéz lenne azt hinnünk, hogy a populációban egyforma magasak a férfiak és a nők, csak nagyon nem volt szerencsénk a mintavétellel.
Egy másik példa: hatásos -e egy antidepresszáns? Tegyük fel, ha a gyógyszert nem szedők PHQ-9 depresszióskálán mért értéke 9, a gyógyszert szedőké pedig 10: ez olyan csekély eltérés, hogy nem állíthatjuk meggyőződéssel, hogy valóban hat a gyógyszer. Lehet, hogy a véletlen szeszélye folytán a gyógyszert nem szedők csoportjába kevésbé depressziós emberek kerültek. Ha ugyanezek az értékek a 0-27-ig terjedő skálán 9 és 14, elgondolkodhatunk; viszont ha 9 és 18, akkor elég világos, hogy az antidepresszáns hat. Hogy valóban ez -e a helyzet a populációban, azt persze nem „érzésre” döntjük el, hanem hipotézisvizsgálattal.
Összefoglalva: az összes hipotézisvizsgálat ezzel a módszertannal dolgozik – vagyis a véletlen, és a tényleges hatás szerepét igyekszik tisztázni; és ehhez a valószínűségszámítás alapvetéseit használja. A jó hír, hogy ha valaki „csak” alkalmazni szeretné ezeket a módszereket, ennél mélyebben nem is szükséges alámerülni a hipotézisvizsgálatok csodás világába. Ha mégis maradt kérdésed, vedd fel velem a kapcsolatot!
Tapasztalataim szerint ez az egyik leginkább misztikusnak tűnő fogalom a statisztikában – és nem csak a diákok számára. Találkoztam már olyan kutatóval is, aki, bár évtizedek óta a pályán van, mégsem érti a lényegét, pedig nem is annyira bonyolult – csak valami furcsa okból épp ez (mármint hogy mi a célunk vele, mi az értelme) szokott kimaradni a statisztika bevezető órákról. Úgyhogy akkor most tisztázzuk is!
Amit mindenképpen érdemes megérteni: a hipotézisvizsgálat mindig a POPULÁCIÓRÓL mond el valamit, a MINTA alapján. Ezért képezik a hipotézisvizsgálatok a következtető statisztika egy jelentős szeletét; a koncepció nyilván mindenkinek ismerős. Van egy sokaság, egy populáció, amit meg szeretnénk ismerni, de nincs módunk megkérdezni/megvizsgálni/lemérni ennek a populációnak minden elemét – kiválasztjuk tehát egy részét(veszünk belőle egy mintát); és ha ezt a kiválasztást sikerült elég precízen megvalósítanunk, akkor a mintából tudunk a teljes populációra következtetni. Ha pedig van egy előzetes feltevésünk a POPULÁCIÓRÓL (például hogy benne azonos a férfiak és a nők átlagmagassága), akkor ezt a feltevést a mintából való következtetéssel tudjuk ellenőrizni – vagyis hipotézisvizsgálatot végzünk.
Emlékszem, amikor én tanultam először erről, én sem értettem a dolgot. Oké, van egy női átlagunk (mondjuk 167), meg egy férfi átlagunk (mondjuk 175), ezeket könnyen kiszámolhatjuk a mintából. Akkor vajon, gondoltam én, miért teszi fel a tanár a szemmel láthatólag szerinte fontos kérdést: „És akkor nézzük meg, eltér -e a nők és a férfiak magassága?”- hát persze hogy eltér, könyörgöm, az egyik 167, a másik 175, a vak is látja, hogy eltér…Azt hiszem, a tanárok már azzal nagyban segítenék a téma megértését, ha ilyenkor kiegészítenék a mondatot, valahogy így: És akkor nézzük meg, eltér -e a nők és a férfiak magassága a POPULÁCIÓBAN (a mintából következtetve…).
Ebből persze az is kiviláglik, hogy ha nem mintavétellel dolgozunk, vagyis ha megvan minden adatunk a populáció elemeiről (mint például egy cégnél az össze munkatárs fizetése), akkor ott értelmetlen hipotézisvizsgálatokat végezni, hiszen nem kell következtetnünk semmire, csak számolnunk kell.
Illetve még egy lényeges kiegészítés: a hipotézisvizsgálatok valószínűségekkel dolgoznak, következésképp BIZTOSAT semmiről a világon nem tudnak mondani – sem pro, sem kontra.
A lényeg tehát, első körben: hipotézisvizsgálatot akkor használunk, ha egy, a populációra vonatkozó feltevésünket akarjuk egy minta alapján igazolni. Ha nincs mintavétel, nincs értelme a hipónak sem; továbbá éppen mivel ismeretlen populációs jelenségekre következtetünk, biztosat a populációról sosem tudunk állítani; nagyon valószínűt vagy valószínűtlent azonban igen.
A lényeg második része hamarosan következik, egy újabb bejegyzésben!