A statisztikában néha problémát okoz a különböző változók eltérő léptéke, mértékegysége. Így van ez a lineáris regressziónál is, ha több magyarázó változót vonunk a modellbe, amelyeknek eltérő a skálázása – ez azt eredményezi, hogy a regressziós együtthatókat nem tudjuk közvetlenül összehasonlítani.
Hiába derítettük ki például, hogy a csontsűrűséget átlagosan 0,2 egységgel növeli, ha 1 decivel több tejet iszunk naponta, és 0,4 egységgel, ha 100 grammal több sajtot fogyasztunk – nem mondhatjuk, hogy a tejfogyasztásnál a sajtfogyasztás kétszer nagyobb hatással van a csontsűrűségre, hiszen a tejet és a sajtot nem azonos mértékegységekkel mértük. Erre a problémára megoldást jelenthet valahogy összehangolni a sajt- és tejfogyasztás skálázását, mondjuk mindkettőt átváltani kalciumtartalomra; de létezik rá tisztán statisztikai módszer is – ezt pedig az SPSS lineáris regresszió outputjába szerencsére bele is építették.
A példa, amin ezt megmutatom, szimulált adatokra épül; azt „vizsgáltam” benne, hogy a félelem a negatív megítéléstől-, és a nárcisztikusság mennyiben befolyásolja a szorongást. Az outputban narancssárgával jelöltem a szokásosan értelmezendő, standardizálatlan, B együtthatókat – ezek szerint tehát a szorongás a neagtív megítéléstől való félelem 0,418 egységnyi növekedésével jár együtt; míg a nárcisztikusság egy egységnyi növekedése a szorongás 0,135 egységnyi csökkenésével (mindhárom változónál azt az eredeti mértékegységet tekintve „egységnek”, amiben eredetileg mértük őket).
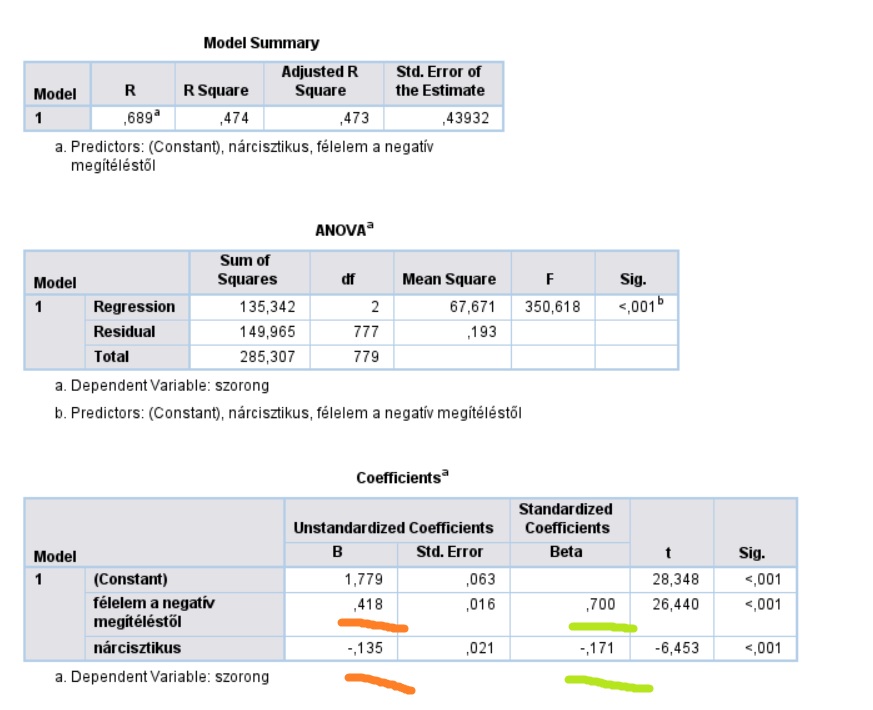
Viszont ha szeretnénk valamit megállapítani a két magyarázó változó hatásának viszonyáról, akkor a zölddel jelölt, standardizált béta együtthatókat kell használnunk! Így tehát azt mondhatjuk, hogy a negatív megítélés nagyjából négyszer akkora (700/171), és ellentétes irányú hatással van a szorongásra, mint a nárcisztikusság.
[Két zárójeles megjegyzés: a regresszió esetében először a két együttható szignifikanciáját figyeljük, ha nincs szignifikáns hatás, magukat az együtthatókat nincs értelme firtatni – épp mert ekkor nincs hatásuk a kimeneti változóra a populációban. A második pedig, hogy a regresszióban csak akkor tudunk „hatásról”, tehát okságról beszélni, ha elméletileg is megalapozott, hogy a magyarázó változó okozza a kimenetit – ha ez nem teljesül, csak a változók „együtt járásáról” beszélhetünk.]