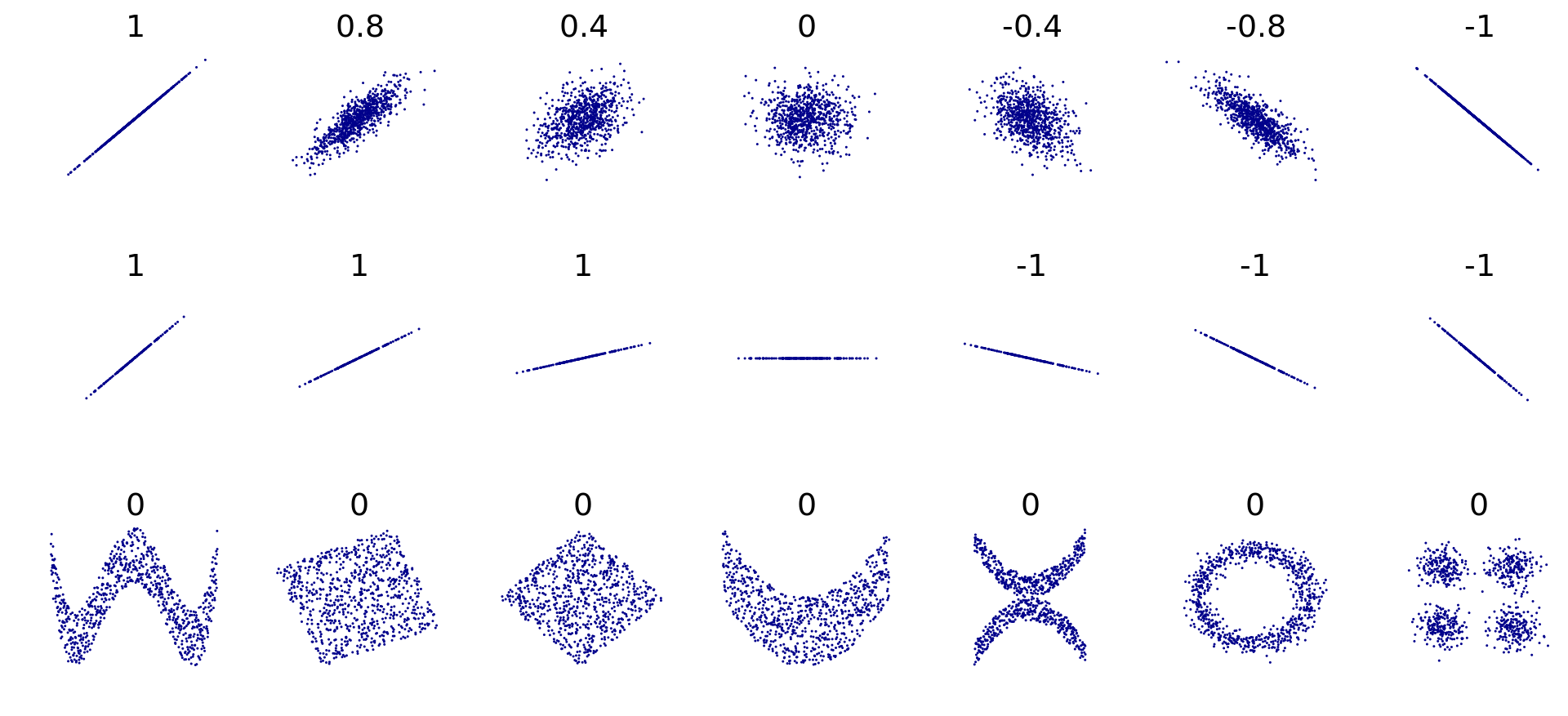
Az egyik kedvenc szakmai feladatom a skálavalidálás. Ilyenkor tulajdonképpen statisztikai módszerekkel bizonyítjuk, hogy egy mérőeszköz valóban azt méri, amit mérni szeretnénk vele.
Erre egy új, frissen kialakított skála esetében lehet szükség; vagy pedig egy olyan skála esetében, amit nemzetközi szinten ismernek és használnak, magyar mintán viszont még nem igazoltuk, hogy megfelelően működik.
Ilyen például az imposztor-szindrómát mérő skála, aminek magyar nyelvű verziójának a validálását éppen most végezzük. Most nem ennek a részleteiről szeretnék írni, hanem arról, hogy ha bármilyen kérdőívben bármit is mérni szeretnél, miért érdemes már validált skálát használni.
Röviden: sokkal komolyabban vehető, szakmailag hitelesebb, és magasabb a presztízse. Ezért azt javaslom, hogy ha akár csak egy beadandóban, pláne a szakdolgozatodban az adatgyűjtést skálák lekérdezésével végzed, akkor ezek a skálák legyenek validáltak.
Valahogy úgy alakul a hierarchia, hogy legjobb, ha azon a populáción validált a skála, ahol a tanulmányaidat folytatod (ha magyar egyetemre jársz, keress magyar mintán validált skálát; ha a holland felsőoktatásban tanulsz, holland mintán validáltat). Ha erre nincs lehetőség, akkor olyat, amit egy olyan országban validáltak, ami tudományos szempontból magas presztízzsel bír; ha ilyet sem találsz, akkor válassz olyan mérőeszközt, amit mások már használtak egy publikációban (nyilván a presztízs itt is szempont, semmiképpen ne az Ezoterika magazinra támaszkodj). Ha pedig olyasmit szeretnél mérni, amire semmiféle, mások által már használt skála nem létezik – csak ebben az esetben állíts össze te magad kérdőívet az adott jelenség felmérésére.